Self-distillation with BAtch Knowledge Ensembling
Improves ImageNet Classification
1. Multimedia Laboratory, The Chinese University of Hong Kong
2. Centre for Perceptual and Interactive Intelligence (CPII)
3. NVIDIA 4. SenseTime Research 5. School of CST, Xidian University
2. Centre for Perceptual and Interactive Intelligence (CPII)
3. NVIDIA 4. SenseTime Research 5. School of CST, Xidian University
Abstract [Full Paper]
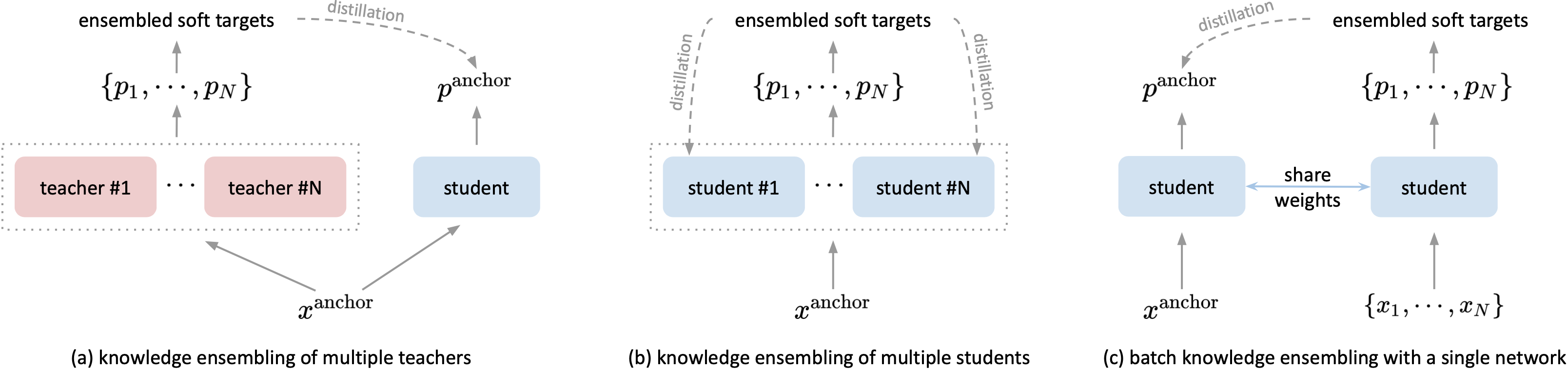
Background:
The recent studies of knowledge distillation have discovered that ensembling the "dark knowledge" from multiple teachers (see (a)) or students (see (b)) contributes to creating better soft targets for training, but at the cost of significantly more computations and/or parameters.
Our Contributions:
- We for the first time introduce to produce ensembled soft targets for self-distillation without using multiple networks or additional network branches.
- We propose a novel BAtch Knowledge Ensembling (BAKE) mechanism to online refine the distillation targets with the cross-sample knowledge, i.e., weightedly aggregating the knowledge from other samples in the same batch (see (c)).
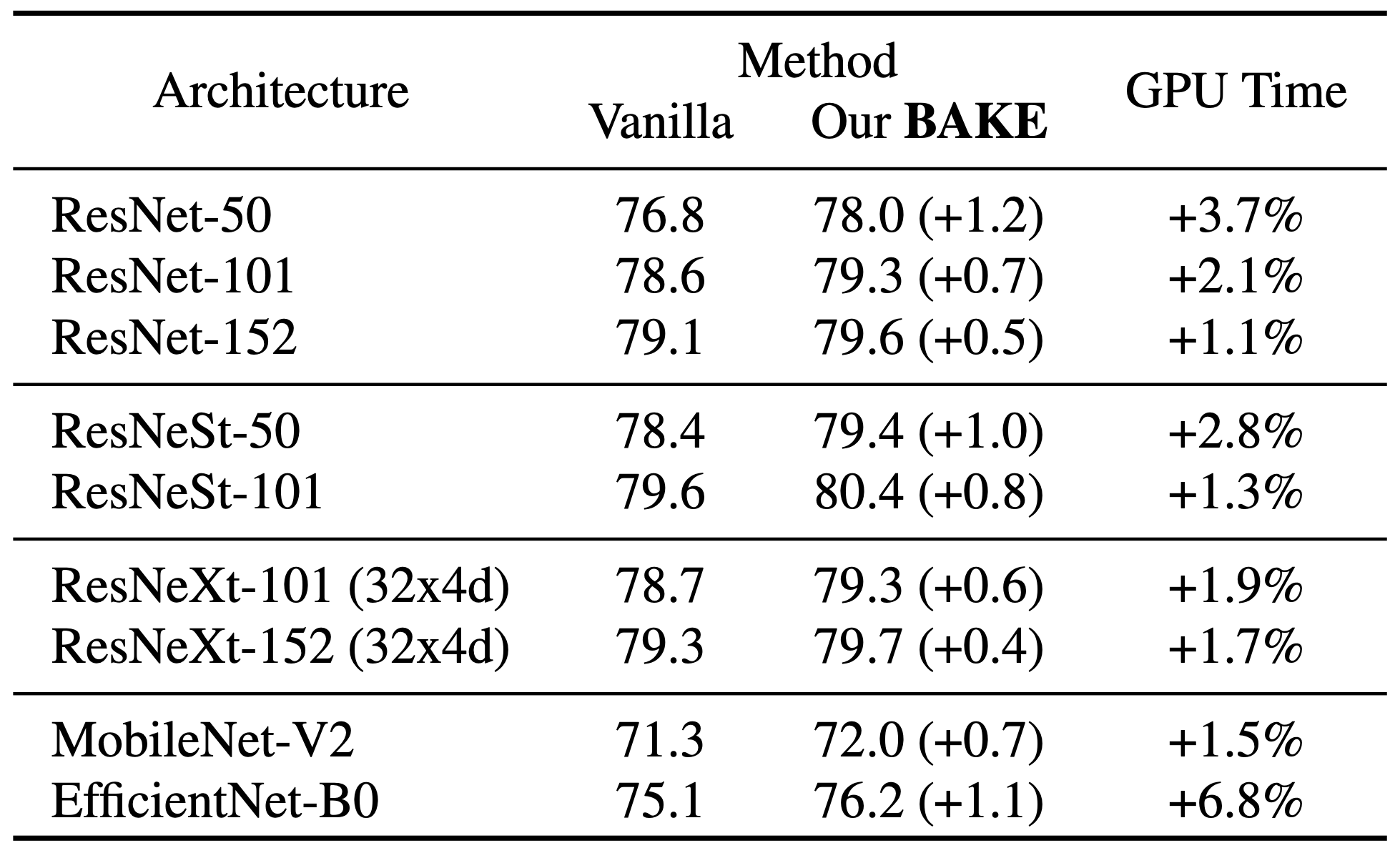
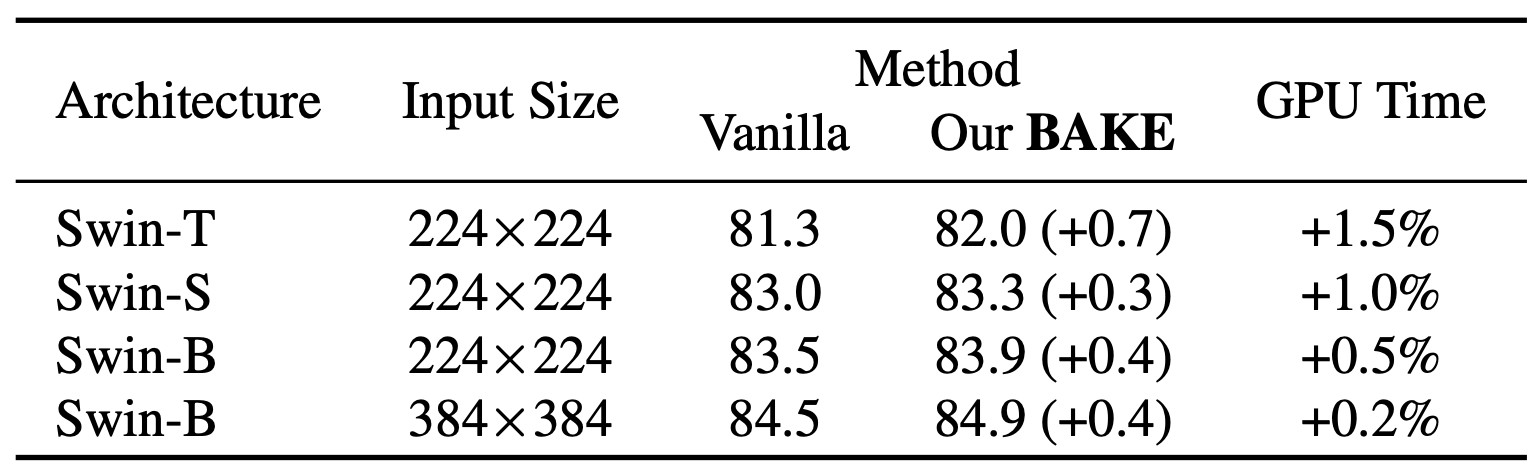
- Our method is simple yet consistently effective on improving classification performances of various networks and datasets with minimal computational overhead and zero additional parameters, e.g., a significant +0.7% gain of Swin-T on ImageNet with only +1.5% computational overhead.
Method Overview
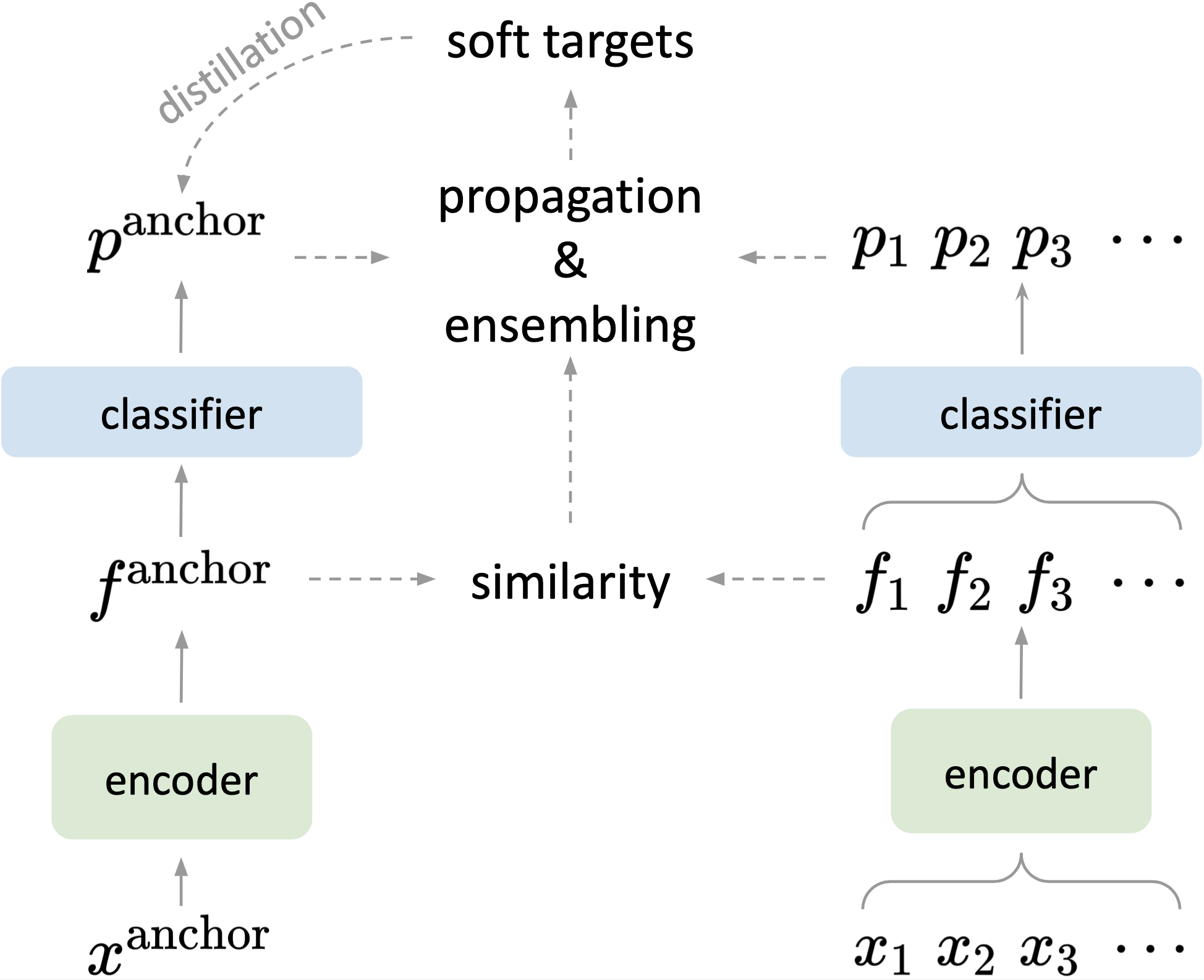

Pseudo Code [Full Code]

Results on ImageNet
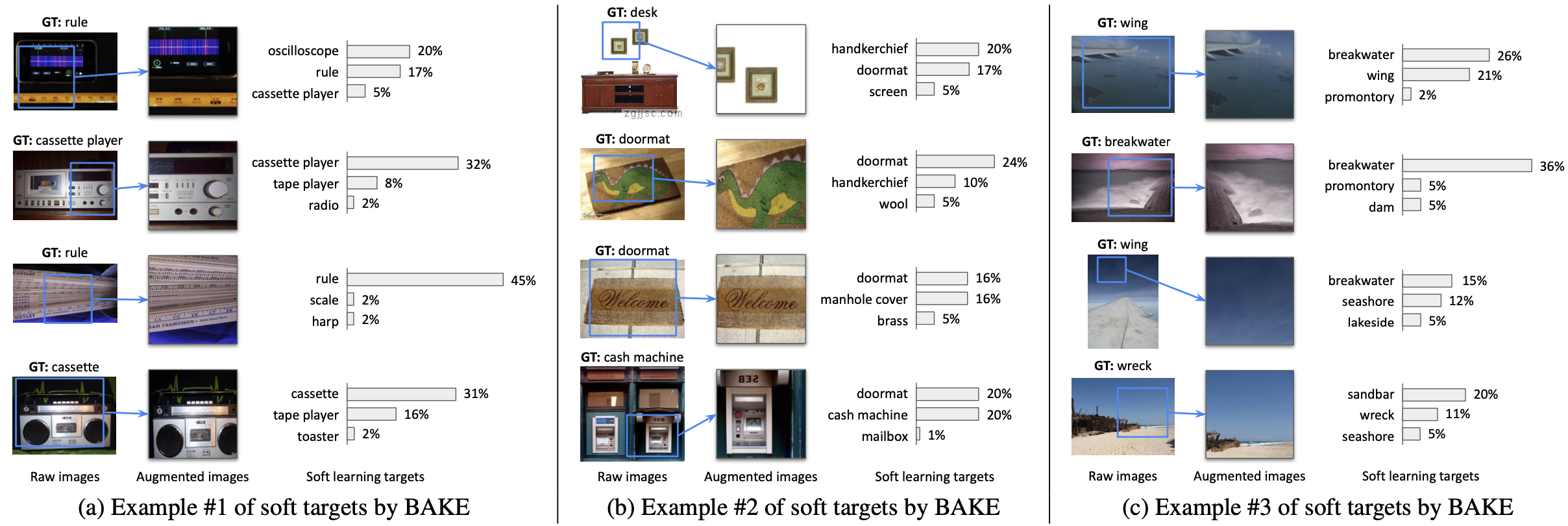
Soft Target Examples on ImageNet
Links


Citation
@misc{ge2020bake,
title={Self-distillation with Batch Knowledge Ensembling Improves ImageNet Classification},
author={Yixiao Ge and Ching Lam Choi and Xiao Zhang and Peipei Zhao and Feng Zhu and Rui Zhao and Hongsheng Li},
year={2021},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
Contact
If you have any question, please contact Yixiao Ge at yxge@link.cuhk.edu.hk.